最近在写爬虫,用的是go的chromedp包。因为其他如gocolly爬虫框架也无法爬取JS动态渲染的页面,只能自己写,并且使用chromdp包。
其中遇到两个问题:
1、每次爬取都要好几秒,大量网页爬取时就是个大问题。
2、解决了上面问题1,又出现context deadline exceed问题。
我们先谈谈第1个问题
网上很多文章都写了chromedp.run()爬取代码,都在生成context时cancel()了,所以再次调用chrome.run()时又要重新生成新的context,相当于重新启动chrome浏览器,所以慢。根据某个网友文章,其实只要暂时不要cancel(),最后一个url爬取以后再cancel()就行,这样相当于还是开着无头浏览器标签,而只是重新打开别的新URL页面而已。
如下代码:
// GetHttpHtmlContent 获取HTML内容
func GetHttpHtmlContent(url string, ctx context.Context) (string, context.Context, context.CancelFunc, error){
var res string
var cancel context.CancelFunc
//新建请求头选项
options := []chromedp.ExecAllocatorOption{
// false意思是展示浏览器窗口,默认true
chromedp.Flag("headless", true),
chromedp.Flag("hide-scrollbars", false),
chromedp.Flag("mute-audio", false),
chromedp.Flag("blink-settings", "imagesEnabled=false"), //不加载图片,提高速度
chromedp.UserAgent(`Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36`),
}
if ctx == nil {
options = append(chromedp.DefaultExecAllocatorOptions[:], options...)
ctx, _ = chromedp.NewExecAllocator(context.Background(), options...)
ctx, _ = chromedp.NewContext(ctx)
}
ctx, cancel = context.WithTimeout(ctx, 60 * time.Second) //60秒超时限制
//defer cancel() //这里隐藏掉cancel,不要在这里做
//远程获取内容并生成pdf
err := chromedp.Run(ctx, chromedp.Tasks{
network.Enable(),
chromedp.Navigate(url),
chromedp.WaitReady("body"),
chromedp.Sleep(200 * time.Millisecond),
chromedp.OuterHTML(`document.querySelector("html")`, &res, chromedp.ByJSPath),
})
return res, ctx, cancel, err
}
下面我们就可以多次执行同个chrome实例,性能快了几倍,之前我测试有6到8秒。现在只要几百毫秒。
func main() {
var ctx context.Context
//第一次传nil的context
url := "http://www.ocara.cn"
s := time.Now()
_, ctx, _, _ = GetHttpHtmlContent(url, nil) //爬取
fmt.Println("use time:", time.Since(s))
//10000次测试。新的都传已生成的context参数ctx
for i := 1; i < 10000; i++ {
var err error
s := time.Now()
_, ctx, _, err = GetHttpHtmlContent(url, ctx) //爬取
if err != nil {
fmt.Println("爬取报错!", err)
break
}
fmt.Println("use time",i, ":", time.Since(s))
}
defer cancel() //最后再进行cancel()
}执行go run main.go,虽然性能达到了 ms级别(其实Sleep()设置到了200ms,减少了休眠时间,如果需要加载图片,有的网页可能加载慢需要调长一点时间,但是随之而来的是爬取时间也会相应地增加)。
但是,出现了context deadline exceed错误,这就是我说的第2个问题。
如下图:
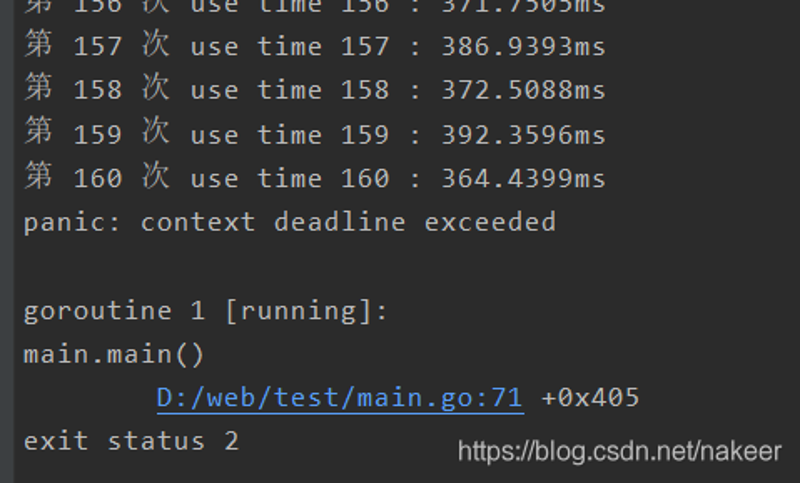
原因是这里因为我们没有cancel()掉context,所以context又设置了超时时间60秒,因为是同一个context生成的子实例相当于同一个chrome标签,所以过了时间会被kill掉。但是我们又不得不设置超时间,因为有的网页就是慢,或者可能打不开网页,如果不设置并且加锁的话(我这里没有加锁)多个协程操作会出现无限等待的可能 。
那既然要设置超时间时间,又出现这个问题,怎么办呢?我想到了已可行的方案,就是在外层调用时进行续期,也就是上面main()函数的for循环里面,判断如果err是context deadline exceed就将ctx设置为nil重新来执行一次,这个其实就是使用conext.DeadlineExceeded来比较的。
如下代码:
func main() {
var ctx context.Context
var cancel context.CancelFunc
url := "http://www.ocara.cn/"
s := time.Now()
_, ctx, _, _ = GetHttpHtmlContent(url, nil)
fmt.Println("use time:", time.Since(s))
for i := 1; i <= 10000; i++ {
var err error
s := time.Now()
_, ctx, cancel, err = GetHttpHtmlContent(url, ctx)
if err != nil {
//续期
if err == context.DeadlineExceeded {
fmt.Println("续期")
_, ctx, _, err = GetHttpHtmlContent(url, nil)
if err != nil {
fmt.Println("续期失败", err)
break
}
} else {
fmt.Println("爬取报错!", err)
break
}
}
fmt.Println("第", i, "次", "use time",i, ":", time.Since(s))
}
defer cancel() //最后再进行cancel()
}
再执行go run main.go,

可以看到,不会报错了,打了续期日志。成功解决第2点问题!
注意:本文归作者所有,未经作者允许,不得转载
